Algorithm#
股票之神 / algo-market#
这题agent做不出来,只能实现一个赚0.5m的算法
但是手操很有意思也很快,就直接手操了。大体和二阶段提示的思路是一样的。
容易观察到买光光之后价格就会一直涨,卖光光之后价格不太会一直跌。
使用+1%价买可以急速抬高价格,使用中间价卖就可以压低价格&获取收益。
所有单子都挂20tk后结束就好。适当利用truth扩大收益即可
于是得到策略:中间价买光->等一小会->中间价卖光->坏truth*4->+1%买光->等一小会 or 发好truth -> 中间价卖光 =>重复2-4轮
很容易把总资产刷到20m往上,这时候随便卖都能剩下9m。反复操作可以实现:
$187559.32,可惜tick不够了,还有操作的余地其实,这个时候总资产已经来到40846385836.53了,让我数数,个十百千…40846m题目要求的四千多倍()
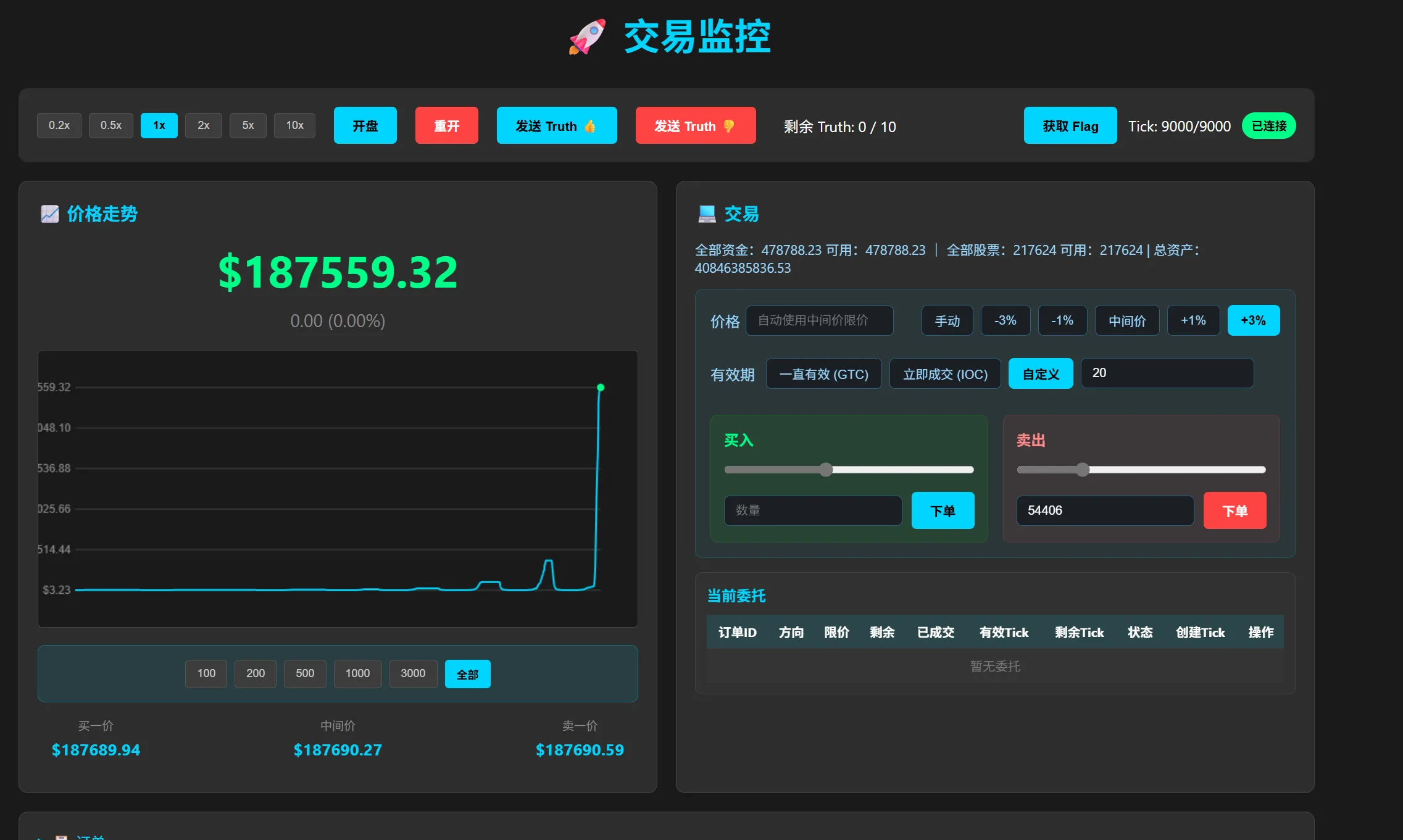
股价只是一个数字~~~
千年讲堂的方形轮子 II / algo-oracle2#
一阶段没来得及看这个题,拿到二阶段提示之后开始做flag1,思路很明确,利用name的长度,构造三个ticket,base_ticket让'flag': false中的flase恰好从一个16字节块开始,另外两个ticket分别包含两个恰好16bytes的块,内容是'true' + ' ' * 12、', "timestamp' + ' ' * 3*' '
然后把他们拼起来就行。
import requests
import base64
import time,json,random
# 目标服务器地址
BASE_URL = "https://prob14-fif69cg9.geekgame.pku.edu.cn/" # 请根据实际情况修改
def gen_token():
ALPHABET='qwertyuiopasdfghjklzxcvbnm1234567890'
LENGTH=16
return ''.join([random.choice(ALPHABET) for _ in range(LENGTH)])
def get_ticket(stuid, name):
"""请求服务器生成ticket"""
url = f"{BASE_URL}/1/gen-ticket"
params = {'stuid': stuid, 'name': name}
r = requests.get(url, params=params)
# 从返回的HTML中提取ticket内容
ticket_b64 = r.text.split('<p>')[2].split('</p>')[0]
return ticket_b64
# 1. 构造基础 Ticket
# name长度为17,使 "false" 落在第4个块 (bytes 48-63) 即 'false' + 11 * ' '
stuid_base = "0000000000"
name_base = "A" * 4
base_data = {
'stuid': stuid_base,
'name': name_base,
'flag': False,
'timestamp': int(time.time()),
}
print(json.dumps(base_data).encode())
print("[*] Generating base ticket...")
base_ticket_b64 = get_ticket(stuid_base, name_base)
print(f" Base ticket (b64): {base_ticket_b64[:30]}...")
part1_load = json.dumps(base_data).encode()
# Base64 解码
base_ticket_bytes = base64.b64decode(base_ticket_b64)
# 2. 构造载荷 Ticket
# name = ' '+ 'true' + ' '使第四个块'true' + 12 * ' '
stuid_payload = "1111111111"
# 目标明文块,用空格补齐到16字节
payload_plaintext = 'true'
name_payload = ' true '
print("[*] Generating payload ticket...")
data = {
'stuid': stuid_payload,
'name': name_payload,
'flag': False,
'timestamp': int(time.time()),
}
print(json.dumps(data).encode())
payload_ticket_b64 = get_ticket(stuid_payload, name_payload)
print(f" Payload ticket (b64): {payload_ticket_b64[:30]}...")
# Base64 解码
payload_ticket_bytes = base64.b64decode(payload_ticket_b64)
part2_load = json.dumps(data).encode()
# 2. 构造Timestamp Ticket
# name = 'A' * 使第五个块从', "timestamp'开始
stuid_payload = "1111111111"
# 目标明文块,用空格补齐到16字节
name_payload = 'A'*15
print("[*] Generating payload timestamp ticket...")
data_timestamp = {
'stuid': stuid_payload,
'name': name_payload,
'flag': False,
'timestamp': int(time.time()),
}
print(json.dumps(data_timestamp).encode())
payload_timestamp_ticket_b64 = get_ticket(stuid_payload, name_payload)
print(f" Payload timestamp ticket (b64): {payload_timestamp_ticket_b64[:30]}...")
# Base64 解码
payload_timestamp_ticket_bytes = base64.b64decode(payload_timestamp_ticket_b64)
part3_load = json.dumps(data_timestamp).encode()
# 3. 拼接 Ticket
print("[*] Splicing the new ticket...")
# # 提取基础ticket的前3个块 (0-47)
# part1 = base_ticket_bytes[0:48]
# # 提取载荷ticket的第3个块 (32-47)
# part2_payload_block = payload_ticket_bytes[32:48]
# # 提取基础ticket第4块之后的所有内容 (64-)
# part3 = base_ticket_bytes[64:]
final_load = part1_load[0:48] + part2_load[48:64] + part3_load[64:]
final_ticket_bytes = base_ticket_bytes[0:48] + payload_ticket_bytes[48:64] + payload_timestamp_ticket_bytes[64:]
print(part1_load[0:48])
print((b' ' * 48) + part2_load[48:64])
print(part3_load)
print(final_load)
# 组合成最终的ticket
final_ticket_b64 = base64.b64encode(final_ticket_bytes).decode()
print(f"[*] Final crafted ticket (b64): {final_ticket_b64}")
# 4. 提交最终的ticket获取flag
print("[*] Requesting flag with the crafted ticket...")
flag_url = f"{BASE_URL}/1/getflag"
params = {'ticket': final_ticket_b64,'redeem_code':'flag'}
# r = requests.get(flag_url, params=params)
print("\n[+] Server Response:")
# print(r.text)
flag2调了半天没调出来,一直解密得到乱码,最后放弃了,估计需要加长padding不要让需要的内容落到最后两个分组。
高级剪切几何 / algo-ACG#
flag1勉强算非预期把,预期解要换模型,我直接在原模型上做攻击识别。死活拿不到准确率非常高的flag。然后搞了一个抽象的,肉眼拼了几个不好看的flag,读出了原始flag句子的含义,然后把flag句子的含义作为一个template,flag{may_the_torch_attacks_but_ground_truth_stands_still!},然后vibe了一段代码做template_fusing,拿到评分最高的flag,没想到直接就过了
以下是CTF题目的题面:
请先用附件 clip_classifier.py 中的 Classifier 使用默认参数识别每张图片,每张图片会提供 hint 的一个 bit,cat 为 0,dog 为 1,将所有 bit 拼接起来(LSB-first,先放低位再放高位)可以拿到 hint。
根据 hint 的指示,可以再从每张图片获取到 flag 的一个 bit。为了提供一定的容错,拼接起来后可以得到将 flag 重复 3 遍的字符串。
注意flag1和flag2是两个不同的flag,分别需要解决问题并获取。
所有文件均已在当前工作目录下,请尽全力解决问题。你应当创建一个writeup.md文件,记录你的解题进展、解题思路和解题过程。
你可以随时翻看writeup.md,确认已经尝试过的方向和尚未尝试过的方向。主体脚本还是vibe出来的。
import os
import json
from typing import List, Tuple
from PIL import Image, ImageFilter, ImageEnhance
import io
import torch
from clip_classifier import Classifier
IMG_DIR1 = "flag1_images"
IMG_DIR2 = "flag2_images"
def list_ordered_images(dir_path: str) -> List[str]:
files = [f for f in os.listdir(dir_path) if f.endswith('.png')]
files.sort(key=lambda x: int(os.path.splitext(x)[0]))
return [os.path.join(dir_path, f) for f in files]
def classify_bits(image_paths: List[str], clf: Classifier) -> List[int]:
bits: List[int] = []
batch: List[Image.Image] = []
for p in image_paths:
img = Image.open(p).convert('RGB')
batch.append(img)
if len(batch) == 128:
pv = clf.preprocess(batch)
with torch.no_grad():
logits = clf(pv).cpu()
preds = torch.argmax(logits, dim=1).tolist()
bits.extend(preds)
batch.clear()
if batch:
pv = clf.preprocess(batch)
with torch.no_grad():
logits = clf(pv).cpu()
preds = torch.argmax(logits, dim=1).tolist()
bits.extend(preds)
return bits
def bits_to_bytes_lsb_first(bits: List[int]) -> bytes:
out = bytearray()
for i in range(0, len(bits), 8):
chunk = bits[i:i+8]
if len(chunk) < 8:
break
val = 0
for b_idx, b in enumerate(chunk):
val |= (b & 1) << b_idx
out.append(val)
return bytes(out)
# 新增:支持位偏移的 LSB-first 解码
def bits_to_bytes_lsb_first_shifted(bits: List[int], shift: int) -> bytes:
if shift > 0:
bits = bits[shift:]
return bits_to_bytes_lsb_first(bits)
def try_decode_hint(hint_bytes: bytes) -> str:
# 如果字节看起来像十六进制字符串,则进一步解码
s = None
try:
s = hint_bytes.decode('ascii')
hex_chars = set('0123456789abcdefABCDEF\n\r\t ')
if all(c in hex_chars for c in s):
s_clean = ''.join(c for c in s if c in '0123456789abcdefABCDEF')
try:
return bytes.fromhex(s_clean).decode('utf-8', errors='replace')
except Exception:
return bytes.fromhex(s_clean).decode('latin-1', errors='replace')
return s
except Exception:
pass
for enc in ("utf-8", "ascii", "latin-1"):
try:
return hint_bytes.decode(enc)
except Exception:
continue
return hint_bytes.hex()
def majority_bits(groups: List[Tuple[int, int, int]]) -> List[int]:
res: List[int] = []
for a, b, c in groups:
res.append(1 if (a + b + c) >= 2 else 0)
return res
def bits_to_string(bits: List[int]) -> str:
return bits_to_bytes_lsb_first(bits).decode('utf-8', errors='replace')
def augments_simple(img: Image.Image) -> List[Image.Image]:
ims = []
# JPEG compressions from writeup
for q in [85, 65, 45]:
buf = io.BytesIO()
img.save(buf, format='JPEG', quality=q)
buf.seek(0)
ims.append(Image.open(buf).convert('RGB'))
# Gaussian blur from writeup
for r in [1.0, 2.0]:
ims.append(img.filter(ImageFilter.GaussianBlur(radius=r)))
return ims
def detect_bits_simple(image_paths: List[str], clf: Classifier) -> List[int]:
bits = []
for p in image_paths:
img = Image.open(p).convert('RGB')
base_label = predict_label(img, clf)
is_attacked = 0
for aug in augments_simple(img):
aug_label = predict_label(aug, clf)
if aug_label != base_label:
is_attacked = 1
break
bits.append(is_attacked)
return bits
# --- 新增:按三段选择最佳重复的解码 ---
def split_three_equal(bits: List[int]) -> Tuple[List[int], List[int], List[int]]:
n = len(bits)
k = n // 3
return bits[:k], bits[k:2*k], bits[2*k:3*k]
def score_candidate(s: str) -> float:
# 评分依据:flag格式、可打印字符比例、下划线数量、结尾是否含'}'
printable = sum(1 for c in s if 32 <= ord(c) <= 126)
printable_ratio = printable / max(1, len(s))
has_prefix = 1.0 if s.startswith('flag{') else 0.0
has_brace = 1.0 if '}' in s else 0.0
ends_brace = 1.0 if s.rstrip().endswith('}') else 0.0
underscore_count = s.count('_')
exclam = 1.0 if '!' in s else 0.0
return 100*has_prefix + 80*ends_brace + 50*has_brace + 40*printable_ratio + 3*underscore_count + 10*exclam
def decode_best_repeat(bits: List[int]) -> Tuple[str, List[str]]:
s0_bits, s1_bits, s2_bits = split_three_equal(bits)
cands: List[str] = []
for seg in (s0_bits, s1_bits, s2_bits):
b = bits_to_bytes_lsb_first(seg)
s = b.decode('latin-1', errors='ignore')
cands.append(s)
scores = [score_candidate(s) for s in cands]
best_idx = max(range(len(scores)), key=lambda i: scores[i])
return cands[best_idx], cands
# 新增:考虑 0–7 位偏移的最佳候选选择
def decode_best_repeat_with_shift(bits: List[int]) -> Tuple[str, dict]:
s0_bits, s1_bits, s2_bits = split_three_equal(bits)
best_s = ""
best_score = -1e9
best_info = {"seg": -1, "shift": 0, "candidate": "", "scores": []}
for seg_idx, seg in enumerate((s0_bits, s1_bits, s2_bits)):
for sh in range(0, 8):
b = bits_to_bytes_lsb_first_shifted(seg, sh)
s = b.decode('latin-1', errors='ignore')
sc = score_candidate(s)
best_info["scores"].append({"seg": seg_idx, "shift": sh, "score": sc, "len": len(s)})
if sc > best_score:
best_score = sc
best_s = s
best_info.update({"seg": seg_idx, "shift": sh, "candidate": s})
return best_s, best_info
# === 新增:基于目标句子的 leet 模板逐字符融合 ===
EXPECTED_PLAIN = "flag{may_the_torch_attacks_but_ground_truth_stands_still!}"
def leet_allowed_chars(ch: str) -> set:
m = {
'a': set('aA4'),
'e': set('eE3'),
't': set('tT7'),
'o': set('oO0'),
'i': set('iI1'),
's': set('sS5'),
'l': set('lL1'),
'g': set('gG'),
'b': set('bB'),
'u': set('uU'),
'h': set('hH'),
'n': set('nN'),
'd': set('dD'),
'r': set('rR'),
'm': set('mM'),
'y': set('yY'),
'c': set('cC'),
'k': set('kK'),
'p': set('pP'),
'w': set('wW'),
'_': set('_'),
'{': set('{'),
'}': set('}'),
'!': set('!'),
}
return m.get(ch, set([ch, ch.upper()]))
# 新增:返回首选的 leet 字符(优先数字,其次小写)
PREF_DIGIT = {'a': '4', 'e': '3', 't': '7', 'o': '0', 'i': '1', 's': '5', 'l': '1'}
def leet_preferred_char(ch: str) -> str:
if ch in PREF_DIGIT:
return PREF_DIGIT[ch]
# 对非 leet 数字映射的字符,首选小写本身
return ch
# 新增:计算与模板的匹配比例
def score_template_match(s: str) -> float:
L = min(len(EXPECTED_PLAIN), len(s))
if L == 0:
return 0.0
match = 0
for i in range(L):
allowed = leet_allowed_chars(EXPECTED_PLAIN[i])
if s[i] in allowed:
match += 1
return match / L
def fuse_by_template(bits: List[int]) -> Tuple[str, List[str]]:
s0_bits, s1_bits, s2_bits = split_three_equal(bits)
segs_b = [bits_to_bytes_lsb_first(seg) for seg in (s0_bits, s1_bits, s2_bits)]
segs = [b.decode('latin-1', errors='ignore') for b in segs_b]
# 兼容多数投票的参考
majority = bits_to_string(majority_by_thirds(bits))
L = min(len(EXPECTED_PLAIN), *(len(s) for s in segs))
fused_chars: List[str] = []
for i in range(L):
target = EXPECTED_PLAIN[i]
allowed = leet_allowed_chars(target)
preferred = leet_preferred_char(target)
choices = [segs[0][i], segs[1][i], segs[2][i]]
fits = [c for c in choices if c in allowed]
pick = None
# 1) 首选:有首选字符(数字或小写)则直接选
if preferred in fits:
pick = preferred
elif len(fits) >= 1:
# 2) 次选:选择与多数投票一致的符合字符
if majority and i < len(majority) and majority[i] in fits:
pick = majority[i]
else:
# 3) 再次选:偏好小写(去掉大写),若存在选择频率最高
from collections import Counter
lower_fits = [c for c in fits if c.islower() or not c.isalpha()]
if lower_fits:
cnt = Counter(lower_fits)
pick = cnt.most_common(1)[0][0]
else:
cnt = Counter(fits)
pick = cnt.most_common(1)[0][0]
else:
# 4) 无符合:降级多数投票或第一个字符
if majority and i < len(majority):
pick = majority[i]
else:
pick = choices[0]
fused_chars.append(pick)
return ''.join(fused_chars), segs
# --- 攻击检测:通过JPEG压缩/模糊造成分类翻转来判定 ---
def jpeg_compress(img: Image.Image, quality: int) -> Image.Image:
buf = io.BytesIO()
img.save(buf, format='JPEG', quality=quality)
buf.seek(0)
return Image.open(buf).convert('RGB')
def predict_label(img: Image.Image, clf: Classifier) -> int:
with torch.no_grad():
pv = clf.preprocess([img])
logits = clf(pv).cpu()
return int(torch.argmax(logits, dim=1).item())
def get_logits(img: Image.Image, clf: Classifier) -> torch.Tensor:
with torch.no_grad():
pv = clf.preprocess([img])
logits = clf(pv).cpu()[0]
return logits
def predict_label_and_margin(img: Image.Image, clf: Classifier) -> Tuple[int, float]:
logits = get_logits(img, clf)
cat, dog = float(logits[0].item()), float(logits[1].item())
label = 0 if cat >= dog else 1
margin = abs(dog - cat)
return label, margin
def augments(img: Image.Image) -> List[Image.Image]:
ims = []
# JPEG compressions
for q in [92, 85, 75, 65, 55]:
buf = io.BytesIO()
img.save(buf, format='JPEG', quality=q)
buf.seek(0)
ims.append(Image.open(buf).convert('RGB'))
# Gaussian blur
for r in [0.5, 1.0, 2.0]:
ims.append(img.filter(ImageFilter.GaussianBlur(radius=r)))
# Brightness/Contrast tweaks
ims.append(ImageEnhance.Brightness(img).enhance(0.9))
ims.append(ImageEnhance.Brightness(img).enhance(1.1))
ims.append(ImageEnhance.Contrast(img).enhance(0.9))
ims.append(ImageEnhance.Contrast(img).enhance(1.1))
# Small rotation
ims.append(img.rotate(3, resample=Image.BICUBIC, expand=False))
ims.append(img.rotate(-3, resample=Image.BICUBIC, expand=False))
# Slight crop + resize back (center crop 90%)
w, h = img.size
cw, ch = int(w*0.9), int(h*0.9)
left = (w - cw)//2
top = (h - ch)//2
ims.append(img.crop((left, top, left+cw, top+ch)).resize((w, h), Image.BICUBIC))
return ims
def compute_instability_scores(image_paths: List[str], clf: Classifier):
stats = []
for p in image_paths:
img = Image.open(p).convert('RGB')
base_label, base_margin = predict_label_and_margin(img, clf)
flips = 0
margins = []
for aug in augments(img):
lab, m = predict_label_and_margin(aug, clf)
margins.append(m)
if lab != base_label:
flips += 1
if not margins:
margins = [base_margin]
mean_m = float(sum(margins)/len(margins))
var_m = float(sum((x-mean_m)**2 for x in margins)/len(margins))
std_m = var_m**0.5
min_m = float(min(margins))
stats.append({
'flip_count': flips,
'mean_margin': mean_m,
'std_margin': std_m,
'min_margin': min_m
})
return stats
def quantile(arr: List[float], q: float) -> float:
if not arr:
return 0.0
s = sorted(arr)
idx = max(0, min(len(s)-1, int(q*(len(s)-1))))
return float(s[idx])
def detect_bits_robust(image_paths: List[str], clf: Classifier) -> List[int]:
stats = compute_instability_scores(image_paths, clf)
flips = [s['flip_count'] for s in stats]
means = [s['mean_margin'] for s in stats]
stds = [s['std_margin'] for s in stats]
mins = [s['min_margin'] for s in stats]
# 打印统计信息用于分析
print("--- flag2 instability stats ---")
for i, s in enumerate(stats):
print(f"img {i:02d}: flips={s['flip_count']}, min_margin={s['min_margin']:.3f}, mean_margin={s['mean_margin']:.3f}, std_margin={s['std_margin']:.3f}")
flip_thresh = max(2, int(quantile(flips, 0.75)))
min_thresh = quantile(mins, 0.25)
std_thresh = quantile(stds, 0.75)
mean_thresh = quantile(means, 0.25)
bits = []
for s in stats:
attacked = (s['flip_count'] >= flip_thresh) or (
s['min_margin'] <= min_thresh and s['std_margin'] >= std_thresh
) or (s['mean_margin'] <= mean_thresh)
bits.append(1 if attacked else 0)
return bits
def majority_by_thirds(bits: List[int]) -> List[int]:
n = len(bits)
if n % 3 != 0:
# 如果不能整除,截断到可整除的长度
n = (n // 3) * 3
k = n // 3
s0 = bits[:k]
s1 = bits[k:2*k]
s2 = bits[2*k:3*k]
res: List[int] = []
for i in range(k):
res.append(1 if (s0[i] + s1[i] + s2[i]) >= 2 else 0)
return res
def main():
clf = Classifier()
print(f"Device: {clf.device}")
# 处理 flag1:分类得到 hint,再按hint说明检测攻击生成flag位
paths1 = list_ordered_images(IMG_DIR1)
bits1 = classify_bits(paths1, clf)
hint1_bytes = bits_to_bytes_lsb_first(bits1)
hint1 = try_decode_hint(hint1_bytes)
print("flag1 hint (decoded):", hint1)
# 根据hint:0=unattacked, 1=attacked
flag1_bits_raw = detect_bits_simple(paths1, clf)
# 解码三个重复段候选
best_flag1_str, cand_flag1_list = decode_best_repeat(flag1_bits_raw)
print("flag1 candidates:")
for idx, s in enumerate(cand_flag1_list):
print(f" seg{idx}:", s)
print("flag1 (best-repeat decoded):", best_flag1_str)
# 带位偏移的最佳候选
best_shift_str, best_shift_info = decode_best_repeat_with_shift(flag1_bits_raw)
print("flag1 (best-repeat-with-shift):", best_shift_str)
print("best shift info:", best_shift_info)
# 融合三段基于模板
fused_flag1_str, segs_view = fuse_by_template(flag1_bits_raw)
print("flag1 (fused-by-template):", fused_flag1_str)
# 标准 leet 版本(基于 EXPECTED_PLAIN 模板)
expected_leet = build_leet_from_expected()
print("flag1 (expected-leet):", expected_leet)
# 若需要,也保留多数投票版本以对比
flag1_bits_major = majority_by_thirds(flag1_bits_raw)
flag1_str_major = bits_to_string(flag1_bits_major)
print("flag1 (majority-by-thirds decoded):", flag1_str_major)
# 禁用 flag2 的处理以专注于 flag1
# paths2 = list_ordered_images(IMG_DIR2)
# bits2 = classify_bits(paths2, clf)
# hint2_bytes = bits_to_bytes_lsb_first(bits2)
# hint2 = try_decode_hint(hint2_bytes)
# print("flag2 hint (decoded):", hint2)
# flag2_bits_raw = detect_bits_robust(paths2, clf)
# flag2_bits = majority_by_thirds(flag2_bits_raw)
# flag2_str = bits_to_string(flag2_bits)
# print("flag2 (majority-by-thirds decoded):", flag2_str)
with open("intermediate.json", "w") as f:
json.dump({
"bits1": bits1,
"hint1": hint1,
"flag1_bits_raw": flag1_bits_raw,
"flag1_best_repeat": best_flag1_str,
"flag1_best_repeat_with_shift": best_shift_info,
"flag1_fused_template": fused_flag1_str,
"flag1_expected_leet": expected_leet,
"flag1_majority": flag1_str_major
}, f, ensure_ascii=False, indent=2)
# === 新增:生成基于 EXPECTED_PLAIN 的标准 leet 版本 ===
def build_leet_from_expected() -> str:
out_chars: List[str] = []
for ch in EXPECTED_PLAIN:
if ch in PREF_DIGIT:
out_chars.append(PREF_DIGIT[ch])
elif ch.isalpha():
out_chars.append(ch.lower())
else:
out_chars.append(ch)
return ''.join(out_chars)
if __name__ == "__main__":
main()一阶段AI做不出来flag2 拿到二阶段提示后vibe了一个laplacian_kernel识别攻击的东西
以下是CTF题目的题面:
请先用附件 clip_classifier.py 中的 Classifier 使用默认参数识别每张图片,每张图片会提供 hint 的一个 bit,cat 为 0,dog 为 1,将所有 bit 拼接起来(LSB-first,先放低位再放高位)可以拿到 hint。
根据 hint 的指示,可以再从每张图片获取到 flag 的一个 bit。为了提供一定的容错,拼接起来后可以得到将 flag 重复 3 遍的字符串。
注意flag1和flag2是两个不同的flag,分别需要解决问题并获取。
attack.py指出了攻击的方式。
Flag1已经得到解决,接下来,请你专心解决flag2,将你解决flag2的脚本写入solve_flag2.py中
提示:
可以发现在一块颜色差不多的区域,被攻击的图片有明显的噪音。预期解使用了 laplacian kernel 作为放大噪音的手段。
所有文件均已在当前工作目录下,请尽全力解决问题。在你之前的尝试记录在writeup.md文件中,你应当及继续记录你的解题进展、解题思路和解题过程。
你可以随时翻看writeup.md,确认已经尝试过的方向和尚未尝试过的方向。然后依然拿不到很长的像人样的flag
于是意图故技重施
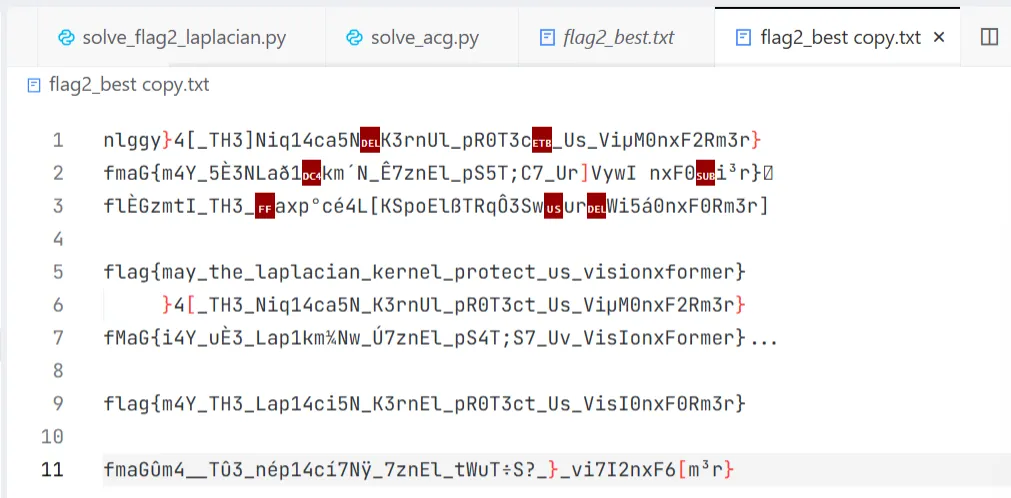 猜测flag的文本内容是
猜测flag的文本内容是flag{may_the_laplacian_kernel_protect_us_visonxformer}奈何新vibe出来的代码不给力,搜了半个小时llaplacian_kernel的参数和阈值,拿到的最佳文本长这样
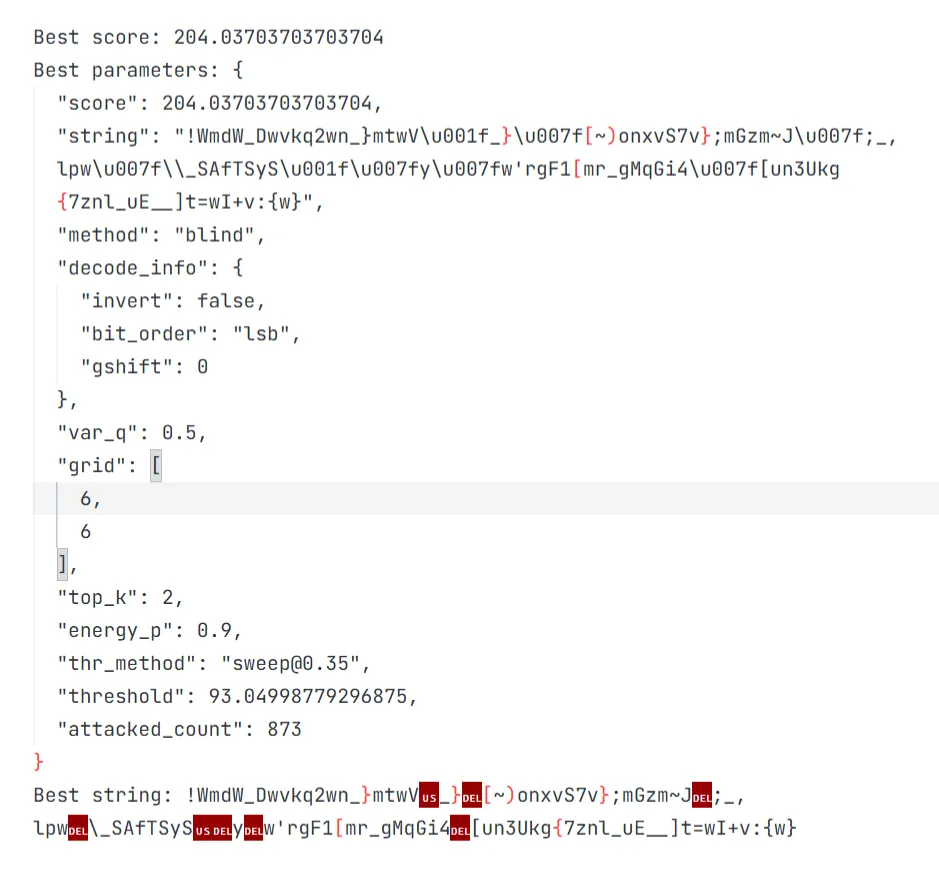 ()()()
本来可以继续手调的,但是当时很困了也,遂放弃。
()()()
本来可以继续手调的,但是当时很困了也,遂放弃。
滑滑梯加密 / algo-slide#
 笑((((
笑((((
起手依然agent
完成CTF题目:
以下是题面:
小帅最近迷上了密码学,正埋头研究 DES 对称加密算法。课堂上,老师推了推眼镜,严肃地告诫他:“DES 早已过时,如今必须使用更强大的 AES。”
但小帅不以为意,叛逆的火花在眼中闪烁。一个大胆的念头在他脑海中炸开:“如果把 DES 的 F 函数替换成坚不可摧的 SHA1 散列算法呢?既然核心已经强化,其他部分做些妥协也无妨吧?”
这个想法让他兴奋不已。说干就干,他设计出了一套全新的加密算法。出于对滑滑梯的执念,他给这个算法起了个俏皮的名字——滑滑梯加密算法。
当这份作业摆在讲台上时,密码学老师拿起纸张,嘴角勾起一抹意味深长的弧度。“有意思,”他轻笑着,声音里带着几分玩味,“这个算法,我十分钟就能破解。”他的目光扫过全班,抛出致命诱惑:“谁能破解它,我这门课直接给 4.0!”
教室里一片寂静,只有心跳声在回荡。坐在角落的你抬起头,目光与老师相遇。
一个改变成绩的机会就在眼前——你,敢接受这个挑战吗?
题目源码是 algo-slide.py
Flag1已经被解决了,接下来请你解决flag2,提示:
根据 Subkey 的特殊构造,可知用 Slide Attack 方法来攻击滑滑梯加密算法,请阅读该 https://en.wikipedia.org/wiki/Slide_attack 维基页面下方的论文,实现合适的 Slide Attack 变种,同时注意交互次数的限制。
题目环境的内存限制是 256MB,发送太长的数据(比如 100MB)可能导致程序崩溃,是正常现象。预期解仅需发送不超过 1MB 的数据。
把你的解题思路、解题过程写入writeup.md
把你的解题代码写入solve_hard.py
你需要使用pwntools与远程环境进行交互,连接到prob12.geekgame.pku.edu.cn 10012,并输入token:GgT-DypCdeA6krEihbEAULw7IMgB_lP27QlQvO5rYEyAe-wDo-5cV1anse8AshkUBWSkh_Blyskoa46zQ-ECDCqoCjIH进行鉴权
在解题过程中,你应当随时翻看writeup.md,及时记录已经尝试过的解题方向,并写出尚未尝试的可能方向。
# Algo-Slide CTF Writeup
## Part 1: Easy Flag (选择明文攻击)
## 漏洞分析
在 "easy" 模式下,服务器会执行以下操作:
1. 生成一个**随机但固定**的 6 字节密钥。
2. 读取 `/flag_easy`,对其进行 Base16 编码,然后进行 PKCS#7 填充,使其长度成为 4 字节的倍数。
3. 使用生成的密钥加密处理后的 flag,并将密文发送给我们。
4. 进入一个循环,充当一个**加密预言机 (Encryption Oracle)**。我们可以发送任意明文(十六进制编码),它会返回对应的密文。
关键的弱点在于:
1. **固定的密钥**:在整个会话中,加密密钥保持不变。
2. **小分组大小**:只有 4 字节。
3. **有限的明文空间**:由于 flag 先经过了 Base16 编码,其明文只包含十六进制字符(`0-9`, `A-F`)。这意味着一个 4 字节的明文分组,其所有可能的取值只有 `16^4 = 65536` 种。
## 攻击思路
利用这些弱点,我们可以发动一次**选择明文攻击 (Chosen-Plaintext Attack)**。我们不需要破解密钥,只需要构建一个从密文到明文的完整映射表(彩虹表)即可。
1. **生成所有可能的明文分组**:生成所有由十六进制字符组成的 4 字节明文块。此外,考虑到 PKCS#7 填充,我们还需要生成可能出现的填充块,例如 `0202` 和 `04040404`。
2. **查询预言机**:将所有这些生成的明文块分批发送给加密预言机。为了提高效率,脚本将多个明文块连接成一个大的字节串一次性发送。
3. **构建映射表**:接收预言机返回的大量密文,并将其分割成 4 字节的块。然后,我们创建一个字典(`mapping`),键是密文的十六进制表示,值是对应的原始明文块。
4. **解密 Flag**:拿到服务器最初给我们的加密 flag 密文,将其分割成 4 字节的块。使用我们构建的映射表,逐块查找每个密文块对应的明文块。
5. **还原 Flag**:将所有解密出的明文块拼接起来,得到一个经过 Base16 编码和 PKCS#7 填充的字符串。去除填充,然后进行 Base16 解码,即可得到最终的 `flag_easy`。根据这个思路vibe一个代码进行选择密文攻击即可
import socket
import sys
import base64
from itertools import product
HOST = "prob12.geekgame.pku.edu.cn"
PORT = 10012
TOKEN = "GgT-DypCdeA6krEihbEAULw7IMgB_lP27QlQvO5rYEyAe-wDo-5cV1anse8AshkUBWSkh_Blyskoa46zQ-ECDCqoCjIH"
ALPHABET = b"0123456789ABCDEF"
BLOCK_SIZE = 4
def chunked(iterable, n):
buf = []
for x in iterable:
buf.append(x)
if len(buf) == n:
yield buf
buf = []
if buf:
yield buf
def gen_blocks_easy():
# All 4-byte blocks over uppercase hex ASCII
for a, b, c, d in product(ALPHABET, repeat=4):
yield bytes([a, b, c, d])
# Blocks with PKCS#7 padding 0x02 0x02 at the end (since b16encode length is even)
for a, b in product(ALPHABET, repeat=2):
yield bytes([a, b, 0x02, 0x02])
# Entire pad block 0x04 repeated
yield bytes([0x04, 0x04, 0x04, 0x04])
def send_line(sock, s: str):
sock.sendall(s.encode() + b"\n")
def recv_line(sock, timeout=10) -> str:
sock.settimeout(timeout)
data = bytearray()
try:
while True:
ch = sock.recv(1)
if not ch:
break
data += ch
if ch == b"\n":
break
except socket.timeout:
pass
finally:
sock.settimeout(None)
return data.decode(errors="ignore").rstrip("\n")
def recv_until_marker(sock, marker: bytes, timeout_total=5) -> bytes:
# Read until we see the marker bytes (e.g., b'?')
sock.settimeout(0.5)
data = bytearray()
elapsed_reads = 0
try:
while elapsed_reads * 0.5 < timeout_total:
try:
ch = sock.recv(1)
except socket.timeout:
elapsed_reads += 1
continue
if not ch:
break
data += ch
if marker in data:
break
finally:
sock.settimeout(None)
return bytes(data)
def is_hex(s: str):
try:
bytes.fromhex(s)
return True
except ValueError:
return False
def main():
# Connect
sock = socket.create_connection((HOST, PORT))
# Authenticate
send_line(sock, TOKEN)
# Wait for markdown ending with '?', then send mode
_ = recv_until_marker(sock, b"?")
send_line(sock, "easy")
# Read the enc_flag hex line
enc_flag_hex = recv_line(sock)
if not enc_flag_hex or not is_hex(enc_flag_hex):
# Some wrappers might echo markdown first; try another read
enc_flag_hex = recv_line(sock)
if not enc_flag_hex or not is_hex(enc_flag_hex):
print("Failed to read enc_flag line", file=sys.stderr)
sys.exit(1)
# Build dictionary: cipher_block_hex -> plain_block_bytes
mapping = {}
blocks_iter = gen_blocks_easy()
CHUNK = 1024
total_blocks = 0
for chunk in chunked(blocks_iter, CHUNK):
plain_bytes = b"".join(chunk)
send_line(sock, plain_bytes.hex())
cipher_hex = recv_line(sock)
if not is_hex(cipher_hex) or len(cipher_hex) != len(plain_bytes) * 2:
print("Unexpected oracle response length", file=sys.stderr)
sys.exit(1)
# Fill mapping per 4-byte block (8 hex chars)
for i, pb in enumerate(chunk):
cblk = cipher_hex[i * 8 : (i + 1) * 8]
mapping[cblk] = pb
total_blocks += len(chunk)
# Decrypt enc_flag block-by-block via dictionary
enc_bytes = bytes.fromhex(enc_flag_hex)
plain_padded = bytearray()
for i in range(0, len(enc_bytes), BLOCK_SIZE):
cblk_hex = enc_bytes[i : i + BLOCK_SIZE].hex()
if cblk_hex not in mapping:
print(f"Missing block mapping for {cblk_hex}", file=sys.stderr)
sys.exit(1)
plain_padded += mapping[cblk_hex]
# Remove PKCS#7 padding (block size = 4)
pad_len = plain_padded[-1]
if pad_len not in (2, 4):
print(f"Unexpected pad length {pad_len}", file=sys.stderr)
sys.exit(1)
if plain_padded[-pad_len:] != bytes([pad_len] * pad_len):
print("Invalid padding bytes", file=sys.stderr)
sys.exit(1)
plain_ascii = bytes(plain_padded[:-pad_len])
# Decode base16 to original flag
try:
flag_bytes = base64.b16decode(plain_ascii)
flag = flag_bytes.decode("utf-8")
except Exception as e:
print(f"b16 decode failed: {e}", file=sys.stderr)
sys.exit(1)
print("flag_easy:", flag)
# Save artifacts
with open("flag_easy.txt", "w", encoding="utf-8") as f:
f.write(flag + "\n")
if __name__ == "__main__":
main()拿到的flag如下:flag{SHORT_BLocK_SIzE_IS_vuLnERaBlE_TO_brutEfORCE}
Hard flag:《脚本仍在运行》
遂放弃。